This is a blog entry I have been thinking about a while. How precise is the ppg (points per pound and gallon) based efficiency calculation really. The reader should see this as something that is interesting to know and more of an exercise in using Plato and sg rather than something that any brewer needs to worry about
When calcylating efficiency (American) home brewers usually use:
(1) Eff = 100 * (gravity points of wort * wort volume) / (grain weight * grain extract potential)
Wort volume is given in gallon, grain weight in pound and extract potential in ppg. But that's not how efficiency is actually defined. It is defined as the ratio between the extract weight in the kettle vs. the extract potential of the grain:
(2) Eff = 100 * extract weight in kettle / grain extract potential
The grain extract potential is simple. It is its weight multiplied with the extract content determined in the laboratory mash. For most base malts it is about 77% (80% dry basis extract and 4% moisture content). Going forward I will call the grains extract potential "e". The weight of the extract in the kettle is a bit more complicated. For that we have to look at the Plato scale. Many brewers know degree Plato as another way of expressing wort strength. To be exact: the wort strength in Plato is the ratio between the weight of the extract dissolved in the wort and the the total wort weight:
(3) P = 100 * extract weight in kettle / wort weight in kettle
Extract weight in kettle is what we need for (2) but I still need the wort weight weight in the kettle. For that I simply remember that sg (specific gravity) is nothing else than the density of the wort in kg/l. It follows that the wort weight in kg is the product of wort volume in l and its specific gravity:
(4) extract weight in kettle = sg * wort volume in kettle
Now I can calculate the actual efficiency by using (2), (3) and (4). First some clean-up and shorter notatons for the variables:
- Eff_ppg = Efficiency calculated using gravity points and ppg for extract potential
- Eff_% = Efficiency calculated using Plato and extract % for grain extract potential
- P = wort strength in Plato
- sg = wort strength in specific gravity (1.xxxx)
- GP = wort gravity points ( = (sg – 1)*1000)
- V_l = wort volume in liter
- V_gal = wort volume in galon
- m_kg = grain weight in kg
- m_lb = grain weight in lb
- e_% = extract potential of the grain in %
- e_ppg = extract potential of the grain in ppg
With that the two efficiencies are:
(5) E_ppg = 100 * GP * V_gal / (m_lb * e_ppg)
(6) E_% = 100 * sg * P * V_l / (m_kg * e_%)
Grain lab analysis results don't show the extract as ppg but as percent of dry weight. To get the ppg equivalent I need to find a formula that calculates e_ppg from e_%. Since it is assumed that both efficicncy calculations (5) and (6) are equal I can set them equal:
(7) E_ppg = E_%
Now the busy work. They both use weight and volumes but in different units. That will be fixed by assuming these conversions:
(8) V_l = V_gal * 3.78
(9) m_kg = m_lb * 0.45
For simplicity I'll be using the simplified Plato to sg conversion. I'll later discuss how much that makes a difference.
(10) P = GP / 4 = (sg – 1) * 250
After putting all this into (5) and (6) I end up with this huge equation:
(11) 100 * (sg – 1) * 1000 * V_gal / (m_lb * e_ppg) = 100 * sg * (sg – 1) * 250 * V_gal * 3.78 / (m_lb * 0.45 * e_%)
Luckily this can be cleaned up considerably. V_gal and m_lb exist on both sides and fall out. So does (sg-1). All the constants can be consolidated into one. What's left is this:
(12) 0.476 / e_ppg = sg / e_%
solving this for e_ppg gives:
(13) e_ppg = 0.476 * e_% / s_g
This equation means that the extract potential in ppg depends on the grains extract potential in %, which is to be expected, and the specific gravity of the wort for which efficicncy is calculated. This was not expected. Here are a few examples. If sugar, which has an extract potential of 100%, is used to make a 1.040 sg wort it has an extract potetial of ~ 46 ppg. If it was used to make a 1.080 sg wort it has an extract potential of only ~ 44 ppg
The same is true for a base malt with 80% dry basis extract and 4% moisture. The actual extract content is 76.8%. If used for 1.040 wort its ppg extract potential is ~36.0 ppg. When used for 1.080 wort the extract potential is ~34.6 ppg.
As a final exercise lets look at a chart that plots the two efficies over the gravity of the wort. The wort volume is held constant while the grain bill is scaled such that the "%" based efficiency remains constant. In addition to that, the sg to Plato conversion is done using the officicial ASBC conversion formula which is a polynominal fit of their sg to Plato tables [deLange]:
(14) P = -616.868 + 1111.14 * sg – 630.272 * sg^2 + 135.997 * sg^3
While there are many similar formulas out there, this is the official one given by the ASBC (American Society of Brewing Chemists) and it should be seen as the standard.
This is the chart I came up with
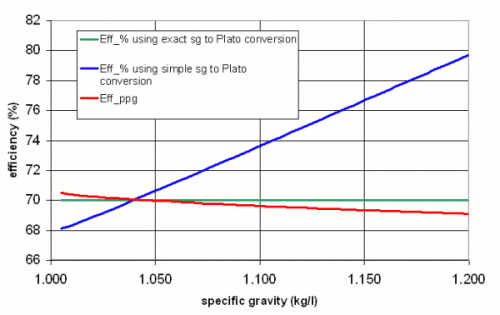
It plots 3 curves. "Eff_% using the exact sg to Plato conversion" uses (14) to convert between sg and Plato. It is constant at 70% because this formula is used to calculate the necessary grain weight for the given volume and specific gravity. "Eff_% using the simple sg to Plato conversion" uses (10) to calculate the sugar content (Plato) from the specific gravity. "Eff_ppg" calculates the efficiency using gravity points and an extract potential of 35.7 ppg.
Despite the existing discrepanacy and incorrectness of the ppg based efficiency calculation, which I discussed earlier in this text, it tracks very well with the actual efficiency of 70% over a wide range of specific gravities. The reson for this is simple: while I showed that technically the extract potential in ppg also depends on the specific gravity, I also simplified the sg to Plato conversion by using (10) instead of (14). Both errors compensate each other to some extend. This also becomes clear when looking at the efficiency which is calculated using the simple sg to Plato conversion. It already shows an error of ~4 percent point at a specific gravity of 1.100.
Conclusions
Does it really matter in brewing whether you use the ppg based forumla or the Plato based one? Not really. If you always use the same formula for efficiency calculation and subsequent recipe design it doesn't matter at all. It may matter when discussing and comparing efficiency with other brewers. In this case the ppg based approach is within 1% of the actual efficiency for all realistic gravities. That error, however, is too small to be a conern in home brewing. Using the % based efficiency calculation with a crude sg to Plato conversion, on the other hand, can overestimate efficiency significantly. Thus care needs to be taken when converting Plato or Brix readings into specific gravity readings. That is in particular true for high gravity worts.
One last word about ppg or "points per pound and gallon". It should be called "point gallons per pound" or pgp since it is an expression of how many "point gallons" (gravity points multiplied with gallons) one can get from one pound of grain, sugar, etc. Its actual unit is gal/lb.
[deLange] A.J. deLange: Specific Gravity Measurement Methods and Applications in Brewing.










 and Dunkel III (right)")

